本篇将介绍,静态数据和流数据,批量计算和实时计算,以及流计算框架Storm。
数据类型与计算模式
静态数据
数仓中存放的大量历史数据就是静态数据。
可利用数据挖掘和OLAP分析工具从这些静态数据中找到价值。
流数据
数据以大量,快速,时变的流形式持续到达。
空气检测为例,实时空气数据不断传回数据中心,对实时数据进行分析。
实时推荐等。
特征:
1.数据快速持续到达
2.数据来源众多,格式复杂
3.数据量大,但不十分关注存储,流数据中某元素,要么被丢弃,要么被归档存储
4.注重数据整体价值,不过分关注个别价值
5.系统无法控制将要处理的新到达的数据元素的顺序。
批量计算
批量计算以静态数据为对象,在充裕的时间内对海量数据进行批量处理,计算得到有价值的信息。
Hadoop是典型的批处理模型。HDFS和HBase存放大量静态数据,由MR负责对海量数据执行批量计算。
实时计算
流数据不适合采用批量计算。实时计算一个需求是能够实时得到计算结果,一般要求相应为秒级。
少量数据时,实时计算不是问题。大数据时代,流计算,应运而生。
流计算
数据采集=》实时分析处理=》结果反馈
流计算秉承的理念:数据的价值随时间的流逝而降低。
流计算系统需求:
1.高性能。每秒几十万。
2.海量式。支持TP,PB。
3.实时性。保证一个较低的延迟时间,秒,毫秒。
4.分布式。支持大数据基本框架,能够平滑扩展。
5.易用性。呢能够快速进行开发和部署。
6.可靠性。能可靠地处理流数据
不同的业务场景,有不同的需求。
流数据的处理流程
数据实时采集:
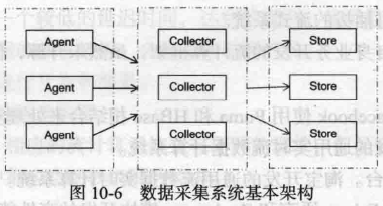
1.Agent:主动采集数据,并把数据推送到Collector部分。
2.Collector:接收多个Agent的数据,并实现有序,可靠,高性能的转发。
3.Store:存储Collector转发过来的数据。
流计算,一般Store部分不进行数据的存储,而是将采集过来的数据直接发送给流计算平台进行实时计算。
数据实时计算:
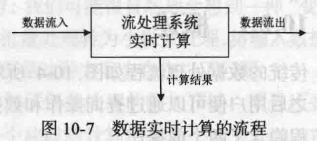
实时查询服务:
流处理系统无需用户主动发出查询,实时查询服务可以主动将实时结果推送给用户。
流计算的应用
场景1:实时分析
例如双11,双12活动仅一天,隔天分析实时数据就失去了价值。
场景2:实时交通
交通信息管理,交通状况查询。
开源框架Storm
特点:
1.整合性。可方便地与队列系统和数据库进行整合。
2.简易的API。API在使用上既简单又方便。
3.可扩展性。并行特性使其可以运行在分布式集群中。
4.容错性。可以自动进行故障节点的充气,以及节点故障时任务的重新分配。
5.可靠的消息处理。保证每个消息都能完整处理。
6.支持各种编程语言。支持使用各种编程语言来定义任务。
7.快速部署。仅需要少量的安装和配置就可以快速进行部署和使用。
8.免费,开源。
Storm设计思想
Tuple:
Tuple是Storm中的主要数据结构。它是有序元素的列表。默认情况下,Tuple支持所有数据类型。通常,它被建模为一组逗号分隔的值,并传递到Storm集群。
Stream:

流是元组的无序序列。一个stream是一个没有边界的tuple序列。
Spout:

Stream流的源头。通常,Storm从原始数据源(如Twitter Streaming API,Apache Kafka队列,Kestrel队列等)接受输入数据并发射成一个流。
Bolts:
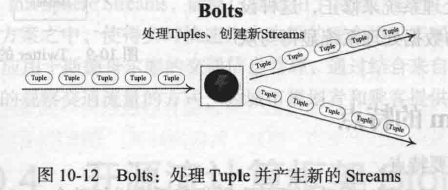
Storm将Stream的状态转换过程抽象为Bolts。Bolts既可以处理Tuple,也可以将处理后的Tuple作为新的Streams发送到其他Bolts。对Tuple的处理逻辑都被封装在Bolts中,可执行过滤,聚合,查询等操作。
Topology:
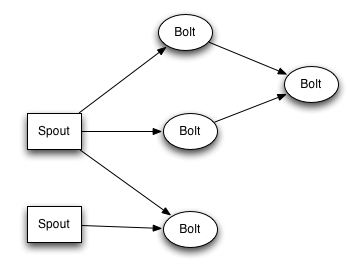
spout和bolt所组成一个网络会被打包成topology, topology是storm里面最高一级的抽象(类似 Job), 你可以把topology提交给storm的集群来运行。topology里面的每一个节点都是并行运行的。
Twitter实例:
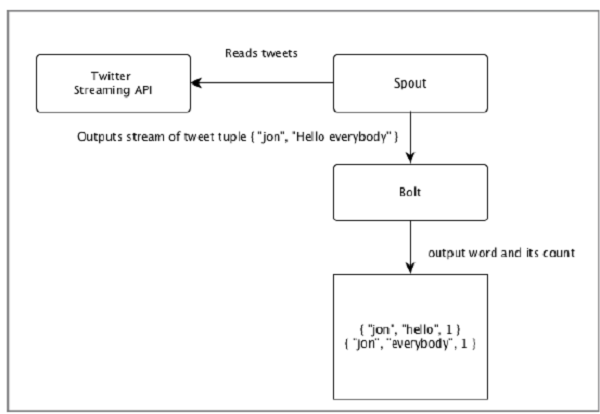
“Twitter分析”的输入来自Twitter Streaming API。Spout将使用Twitter Streaming API读取用户的tweets,并作为元组流输出。来自spout的单个元组将具有twitter用户名和单个tweet作为逗号分隔值。然后,这个元组的蒸汽将被转发到Bolt,并且Bolt将tweet拆分成单个字,计算字数,并将信息保存到配置的数据源。现在,我们可以通过查询数据源轻松获得结果。
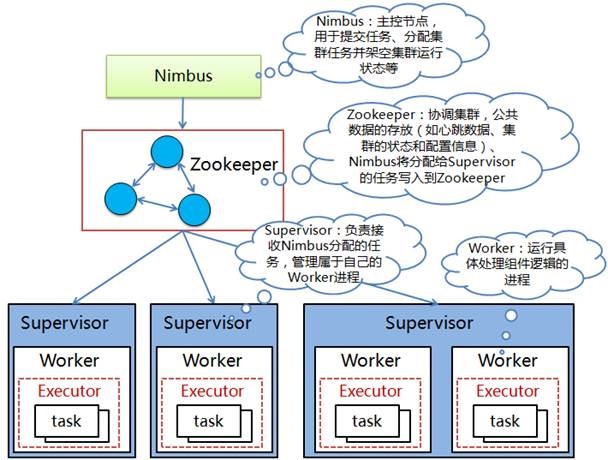
Storm的框架设计
Strom运行在分布式集群中,其运行任务的方式与Hadoop类似。
Hadoop上运行的是MR,Storm上运行的是Topology。
Storm集群采用‘Master worker’节点方式。
其中Master节点运行名为Nimbus的后台程序(类似Hadoop中的JobTracker),负责在集群内分发代码,为Worker分配任务,检测故障。每个Worker节点运行名为Supervisor的后台程序,负责监听分配给它所在机器的工作,根据Nimbus分配的任务来决定启动或停止Worker进程。
Zookeeper作为分布式协调组件,负责Nimbus和多个Supervisor之间的所有协调工作。
Master节点没有直接和worker节点通信,借助Zookeeper,节点故障时快速恢复。