HBase是 BigTable 的开源版本,是建立在 HDFS 之上的 NoSQL 数据库。
出现背景
(1)海量数据量存储成为瓶颈,单台机器无法负载大量数据
(2)单台机器 IO 读写请求成为海量数据存储时候高并发大规模请求的瓶颈
(3)随着数据规模越来越大,大量业务场景开始考虑数据存储横向水平扩展,使得存储服务可以增加/删除,而目前的关系型数据库更专注于一台机器
- HBase 是 BigTable 的开源(源码使用 Java 编写)版本。是 Apache Hadoop 的数据库,是建立在 HDFS 之上,被设计用来提供高可靠性、高性能、列存储、可伸缩、多版本的 NoSQL 的分布式数据存储系统,实现对大型数据的实时、随机的读写访问。
- HBase 依赖于 HDFS 做底层的数据存储,BigTable 依赖 Google GFS 做数据存储
- HBase 依赖于 MapReduce 做数据计算,BigTable 依赖 Google MapReduce 做数据计算
- HBase 依赖于 ZooKeeper 做服务协调,BigTable 依赖 Google Chubby 做服务协调
表的特点
1、大:一个表可以有上十亿行,上百万列
2、面向列:面向列(族)的存储和权限控制,列(簇)独立检索。
3、稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
4、无模式:每行都有一个可排序的主键和任意多的列,列可以根据需要动态的增加,同一张表中不同的行可以有截然不同的列
与关系型数据库的区别
| RDMS | HBase | |
|---|---|---|
| 数据类型 | 采用关系模型,具有丰富的数据类型和存储模式。 | 数据存储为未经解释的字符串,把不同格式结构化非结构化的数据都序列化成字符串保存到HBase中,用户需自己编程把字符串解释成不用的数据类型。 |
| 数据操作 | 操作丰富,如插入,删除,更新,查询等,不要多表连接。 | 没有复杂的表与表之间的关系,只有插入,查询,删除,清空等,无法操作表与表之间。 |
| 存储模式 | 基于行模式存储,元组或行会被连续存储在磁盘页中,读取数据需要顺序扫描每个元组,从中筛选删出查询所需要的属性,如果只有少量属性有用,则会浪费很多内存和宽带。 | 基于列存储,每个列族由好几个文件保存,不用列族的文件是分离的,优点是降低I/O开销,支持大量并发用户查询,仅需要处理可以回答这些查询的列,同一列族数据会被压缩,因为相似,压缩比较高。 |
| 数据索引 | 可针对不同列构建复杂的多个索引。 | 只有一个索引,行键。Hbase所有的访问方法,或者用过行键访问,或者用过行键扫描。可以使用MR生成索引表。 |
| 数据维护 | 更新之后新值会覆盖旧值,旧值覆盖后不存在。 | 更新时不会删除数据的旧版本,而是生成一个新版本,旧版本仍然保留。 |
| 可伸缩性 | 很难横向扩展,纵向扩展的空间也有限。 | 分布式数据库就是为了实现灵活扩展而开发,能够轻易通过在集群中增加或者减少硬件数量来实现性能的伸缩。 |
数据类型
HBase实际上是一个稀疏,多维,持久化存储的映射表。
采用行键,列族,列限定符,时间戳进行索引,每个值都是未经解释的字节数组byte[]。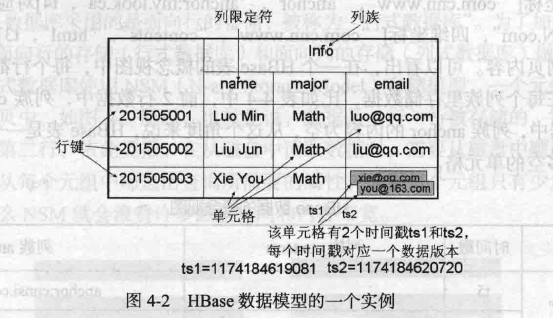
1.表
HBase使用表组织数据,表由行和列组成,列划分为多个列族。
2.行
每个HBase都由若干行组成,每个行由行键(Row Key)标识。
访问表中的行有三种方式:
(1)通过单个行键访问
(2)通过一个行键的区间访问
(3)全表扫描
行键可以是任意字符串,在内部保存为字节数组。
存储时,数据按照行键的字典顺序排列。将经常存储的行键存储在一起。
3.列族
一个表被分组成许多列族的集合,它是基本的访问控制单元。
列族需要在创建表时就定义好,数量不能太多(仅限几十个),不要频繁修改。
借助列族控制权限,可以实现特定目的,例如允许一些应用能够向表中添加新数据,
另一些只浏览数据。列族也可以被配置成支持不用类型的访问模式,如放入内存。
4.列限定符
列族里数据通过列限定符(或列)来定位。列限定符不用事先定义。
5.单元格
表中,通过行,列族和列限定符确定一个“单元格”(cell)。
每个单元格中可以保存一个数据的多个版本,每个版本对应一个不同的时间戳。
6.时间戳
每个单元格保存着同一份数据的多个版本。这些版本通过时间戳进行索引。
对单元格执行操作时(新建,修改,删除)时,HBase会隐式自动生成并存储一个时间戳。
时间戳一般是64位整型。可以自己赋值,也可以自动赋值。
根据时间,降序存储。
数据坐标
关系型数据库数据库可以理解为“二维坐标”,根据行和列确定一个具体的值。
[行,列]
HBase中根据行键,列族,列,时间戳来确定一个单元格,“四维坐标”。
[行键,列族,列限定符,时间戳]
例如上图中:
实现原理
3个主要功能组件:
- 库函数,连接到每个客户端;
- 一个Master主服务器;
- 许多个Region服务器。
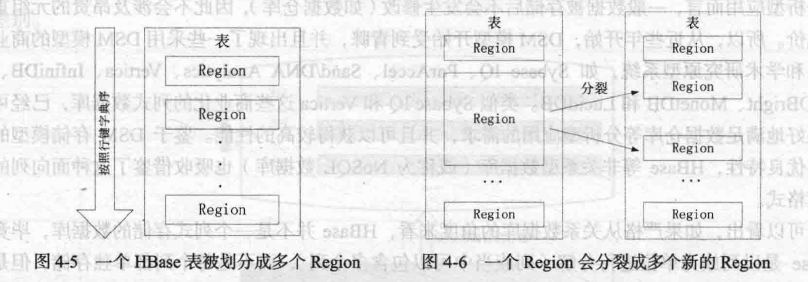
Hbase中表需要根据行键值进行分区,行区间构成一个分区,别成为‘Region’,包含了某个域值区间内的所有数据。是负载均衡分发的基本单位。这些Region会被分发到不用的Region服务上。
初始时,每个表只包含一个Region,随着数据插入,持续增大,分裂。
三层结构
名称和作用
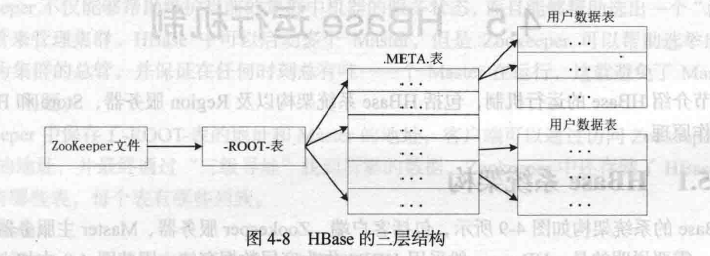
系统架构

为什么快
A:快速查询
如果快速查询(从磁盘读数据),hbase是根据rowkey查询的,只要能快速的定位rowkey, 就能实现快速的查询,主要是以下因素:
1、hbase是可划分成多个region,你可以简单的理解为关系型数据库的多个分区。
2、键是排好序了的
3、按列存储的
首先,能快速找到行所在的region(分区),假设表有10亿条记录,占空间1TB, 分列成了500个region, 1个region占2个G. 最多读取2G的记录,就能找到对应记录;
其次,是按列存储的,其实是列族,假设分为3个列族,每个列族就是666M, 如果要查询的东西在其中1个列族上,1个列族包含1个或者多个HStoreFile,假设一个HStoreFile是128M, 该列族包含5个HStoreFile在磁盘上. 剩下的在内存中。
再次,是排好序了的,你要的记录有可能在最前面,也有可能在最后面,假设在中间,我们只需遍历2.5个HStoreFile共300M
最后,每个HStoreFile(HFile的封装),是以键值对(key-value)方式存储,只要遍历一个个数据块中的key的位置,并判断符合条件可以了。 一般key是有限的长度,假设跟value是1:19(忽略HFile上其它块),最终只需要15M就可获取的对应的记录,按照磁盘的访问100M/S,只需0.15秒。 加上块缓存机制(LRU原则),会取得更高的效率。
B:实时查询
实时查询,可以认为是从内存中查询,一般响应时间在1秒内。HBase的机制是数据先写入到内存中,当数据量达到一定的量(如128M),再写入磁盘中, 在内存中,是不进行数据的更新或合并操作的,只增加数据,这使得用户的写操作只要进入内存中就可以立即返回,保证了HBase I/O的高性能。
实时查询,即反应根据当前时间的数据,可以认为这些数据始终是在内存的,保证了数据的实时响应。