神经网络优化主要为通过反向传播算法训练网络参数,在反向传播中,通过优化损失函数,学习率,使用滑动平均,正则化等方法优化网络参数,使神经网络的预测更加准确。
1.基本网络
上一篇中back.py中的网络模型: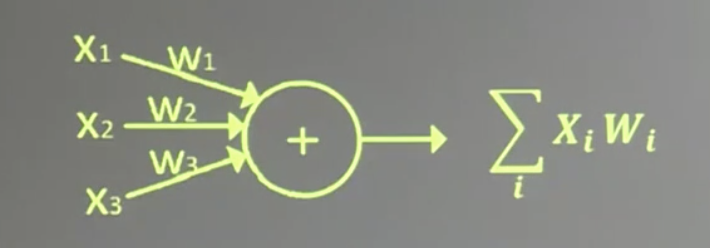
传统网络模型: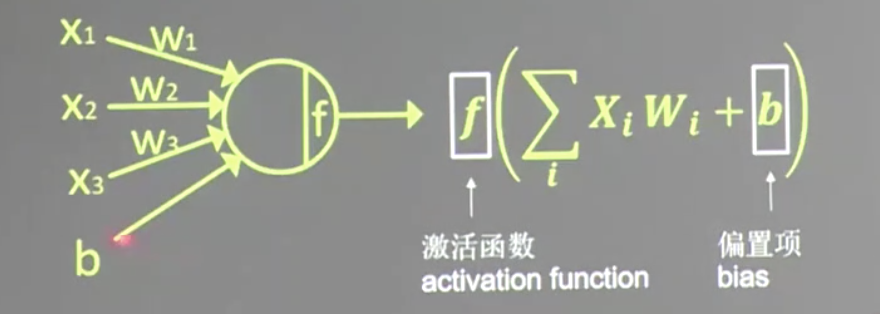
神经元模型:
用数学公式表示为:𝐟(∑𝒊𝒙𝒊𝒘𝒊 + 𝐛),f为激活函数。神经网络是以神经元为基本单元构成的。
激活函数:
引入非线性激活因素,提高模型的表达力。常用的激活函数有relu、sigmoid、tanh等。
激活函数relu: 在Tensorflow中,用tf.nn.relu()表示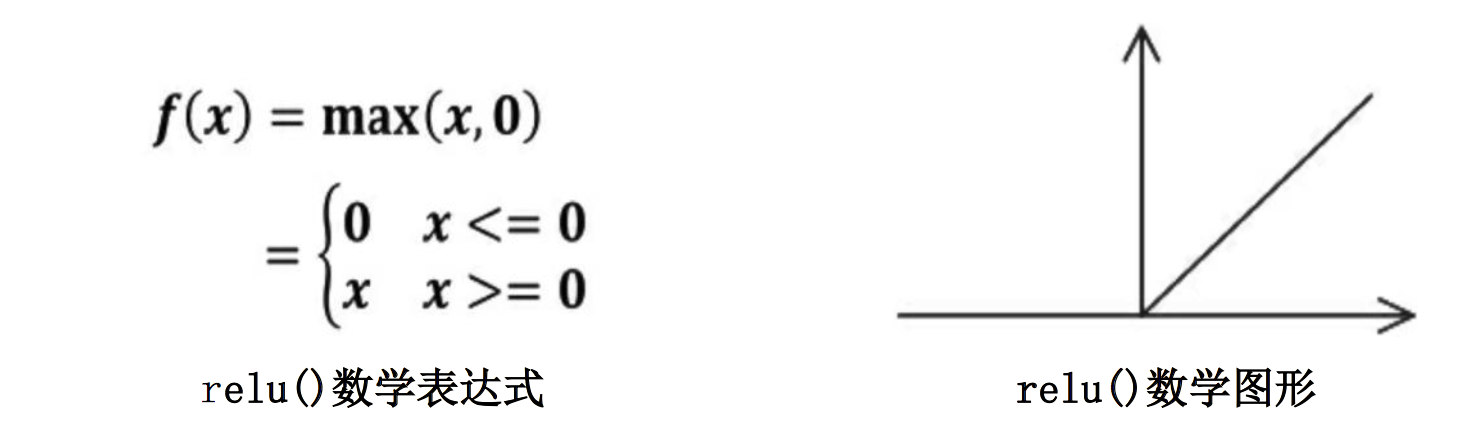
激活函数 sigmoid:在Tensorflow中,用tf.nn.sigmoid()表示
激活函数tanh:在Tensorflow 中,用tf.nn.tanh()表示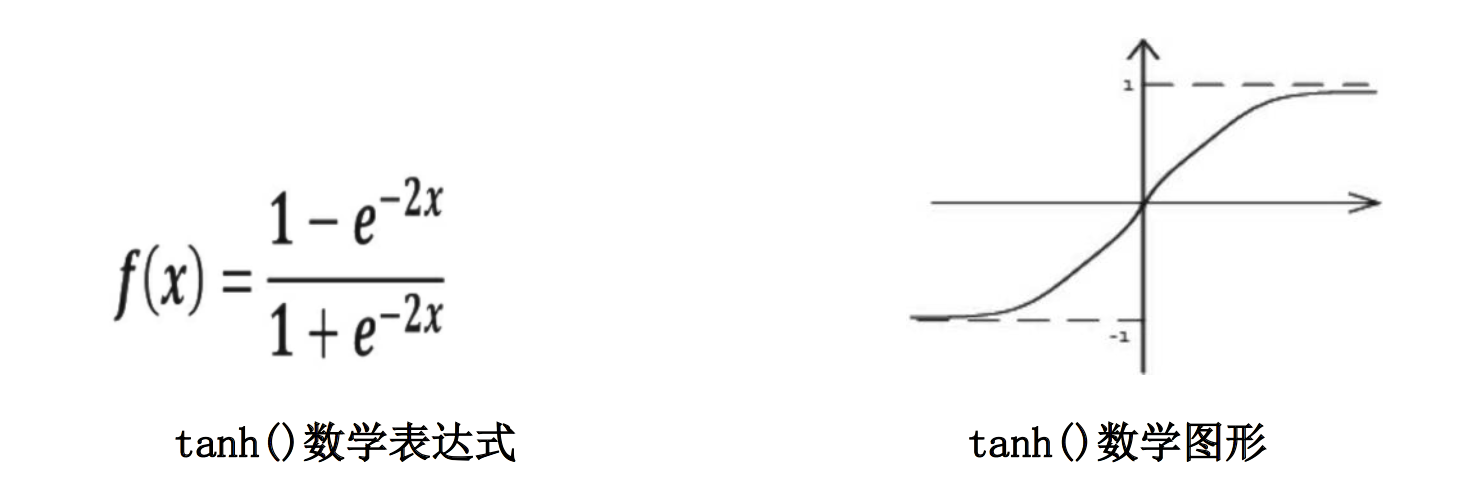
神经网络的复杂度:可用神经网络的层数和神经网络中待优化参数个数表示
神经网路的层数:一般不计入输入层,层数 = n 个隐藏层 + 1 个输出层
神经网路待优化的参数:神经网络中所有参数 w 的个数 + 所有参数 b 的个数
例如: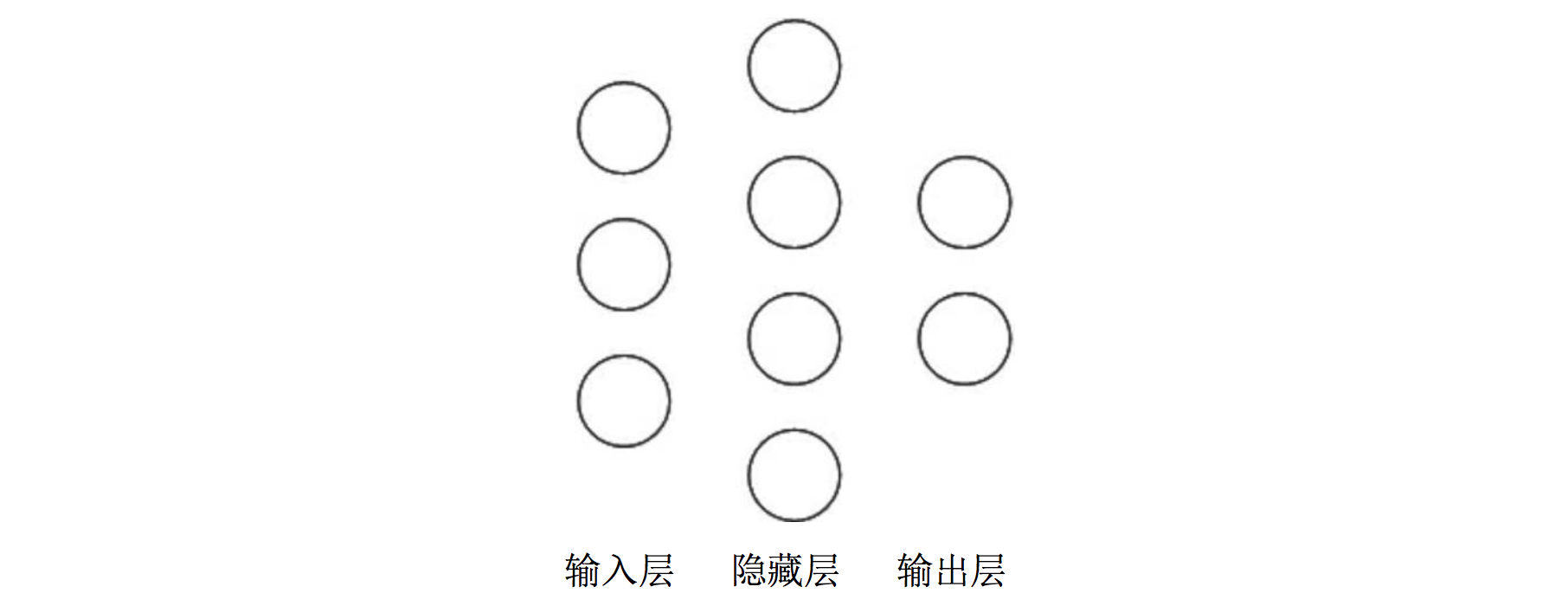
在该神经网络中,包含 1 个输入层、1 个隐藏层和 1 个输出层,该神经网络的层数为 2 层。 在该神经网络中,参数的个数是所有参数 w 的个数加上所有参数 b 的总数,第一层参数用三行四列的 二阶张量表示(即 12 个线上的权重 w)再加上 4 个偏置 b;第二层参数是四行两列的二阶张量()即 8 个线上的权重 w)再加上 2 个偏置 b。总参数 = 34+4 + 42+2 = 26。
2.损失函数
损失函数(loss):
用来表示预测值(y)与已知答案(y_)的差距。在训练神经网络时,通过不断改变神经网络中所有参数,使损失函数不断减小,从而训练出更高准确率的神经网络模型。
常用的损失函数有均方误差、自定义和交叉熵等。
均方误差(mse):
n个样本的预测值y与已知答案y_之差的平方和,再求平均值。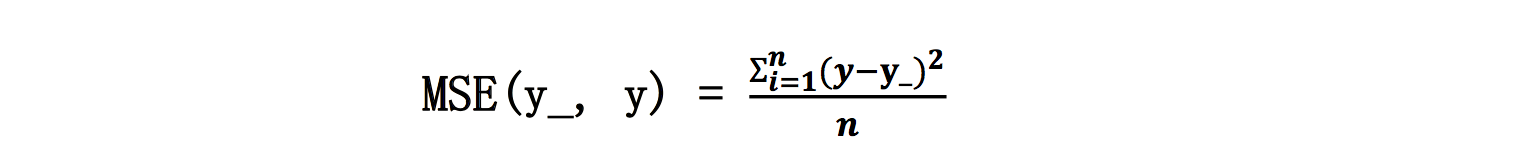
在Tensorflow中用loss_mse = tf.reduce_mean(tf.square(y_ - y))
例如:
预测酸奶日销量 y,x1 和 x2 是影响日销量的两个因素。
应提前采集的数据有:一段时间内,每日的 x1 因素、x2 因素和销量 y_。采集的数据尽量多。
在本例中用销量预测产量,最优的产量应该等于销量。由于目前没有数据集,所以拟造了一套数据集。利用 Tensorflow 中函数随机生成 x1、 x2,制造标准答案 y_ = x1 + x2,为了更真实,求和后还加了正负 0.05 的随机噪声。
我们把这套自制的数据集喂入神经网络,构建一个一层的神经网络,拟合预测酸奶日销量的函数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37#coding:utf-8
#预测多或预测少的影响一样
#0导入模块,生成数据集
import tensorflow as tf
import numpy as np
BATCH_SIZE = 8
SEED = 23455
rdm = np.random.RandomState(SEED)
X = rdm.rand(32,2)
Y_ = [[x1+x2+(rdm.rand()/10.0-0.05)] for (x1, x2) in X]
#1定义神经网络的输入、参数和输出,定义前向传播过程。
x = tf.placeholder(tf.float32, shape=(None, 2))
y_ = tf.placeholder(tf.float32, shape=(None, 1))
w1= tf.Variable(tf.random_normal([2, 1], stddev=1, seed=1))
y = tf.matmul(x, w1)
#2定义损失函数及反向传播方法。
#定义损失函数为MSE,反向传播方法为梯度下降。
loss_mse = tf.reduce_mean(tf.square(y_ - y))
train_step = tf.train.GradientDescentOptimizer(0.001).minimize(loss_mse)
#3生成会话,训练STEPS轮
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
STEPS = 20000
for i in range(STEPS):
start = (i*BATCH_SIZE) % 32
end = (i*BATCH_SIZE) % 32 + BATCH_SIZE
sess.run(train_step, feed_dict={x: X[start:end], y_: Y_[start:end]})
if i % 500 == 0:
print "After %d training steps, w1 is: " % (i)
print sess.run(w1), "\n"
print "Final w1 is: \n", sess.run(w1)
#在本代码#2中尝试其他反向传播方法,看对收敛速度的影响
本例中神经网络预测模型为 y = w1x1 + w2x2,损失函数采用均方误差。通过使 损失函数值(loss)不断降低,神经网络模型得到最终参数 w1=0.98,w2=1.02,销量预测结果为 y = 0.98x1 + 1.02x2。由于在生成数据集时,标准答案为 y = x1+x2,因此,销量预测结果和标准 答案已非常接近,说明该神经网络预测酸奶日销量正确。
交叉熵(Cross Entropy):
表示两个概率分布之间的距离。交叉熵越大,两个概率分布距离越远,两个概率分布越相异;交叉熵越小,两个概率分布距离越近,两个概率分布越相似。
交叉熵计算公式:𝐇(𝐲_ , 𝐲) = −∑𝐲_ ∗ 𝒍𝒐𝒈 𝒚
用Tensorflow函数表示为
ce= -tf.reduce_mean(y_ tf.log(tf.clip_by_value(y, 1e-12, 1.0)))
例如:
两个神经网络模型解决二分类问题中,已知标准答案为 y_ = (1, 0),第一个神经网络模型预测结果为y1=(0.6, 0.4),第二个神经网络模型预测结果为 y2=(0.8, 0.2),判断哪个神经网络模型预测的结果更接近标准答案。
根据交叉熵的计算公式得:
H1((1,0),(0.6,0.4)) = -(1log0.6 + 0log0.4) ≈ -(-0.222 + 0) = 0.222
H2((1,0),(0.8,0.2)) = -(1log0.8 + 0*log0.2) ≈ -(-0.097 + 0) = 0.097
由于 0.222>0.097,所以预测结果 y2 与标准答案 y_更接近,y2 预测更准确。
自定义损失函数:
根据问题的实际情况,定制合理的损失函数。
代码实现参考Github:
opt_loss.py
opt_mse.py