反向传播算法是训练模型的核心算法,他可以根据定义好的损失函数优化神经网络中的参数取值,本篇在所有参数上用梯度下降,使NN模型在训练数据上的损失函数最小。
损失函数(loss):
计算得到的预测值y与已知答案y_的差距。
损失函数的计算有很多方法,均方误差MSE是比较常用的方法之一。
均方误差MSE:
求前向传播计算结果与已知答案之差的平方再求平均。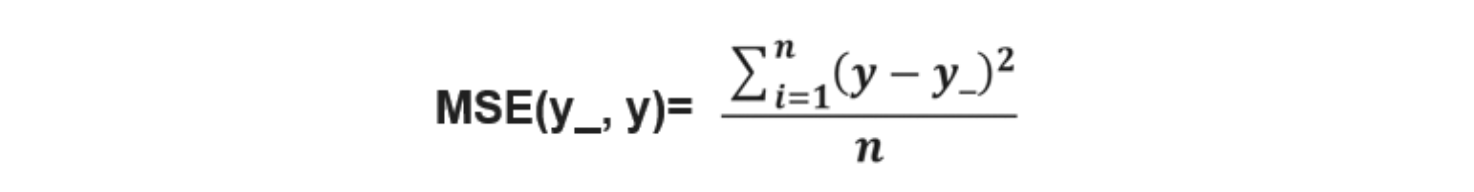
反向传播训练方法:
以减小loss值为优化目标,有梯度下降、momentum优化器、adam优化器等优化方法。
这三种优化方法用 tensorflow 的函数可以表示为:
train_step=tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
train_step=tf.train.MomentumOptimizer(learning_rate, momentum).minimize(loss)
train_step=tf.train.AdamOptimizer(learning_rate).minimize(loss)
三种优化方法区别如下:
1.tf.train.GradientDescentOptimizer()
使用随机梯度下降算法,使参数沿着梯度的反方向,即总损失减小的方向移动,实现更新参数。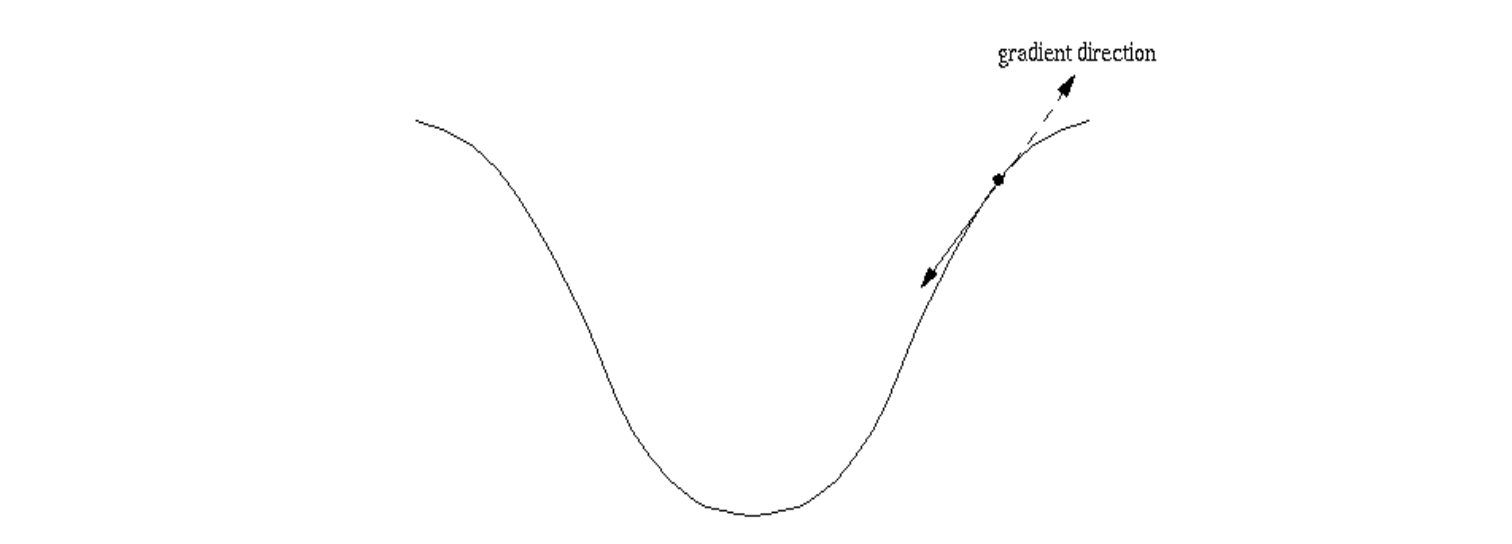
参数更新公式是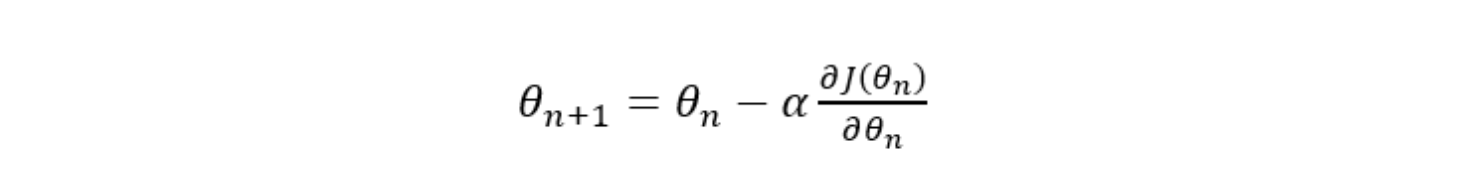
其中,𝐽(𝜃)为损失函数,𝜃为参数,𝛼为学习率。
2.tf.train.MomentumOptimizer()
在更新参数时,利用了超参数,参数更新公式是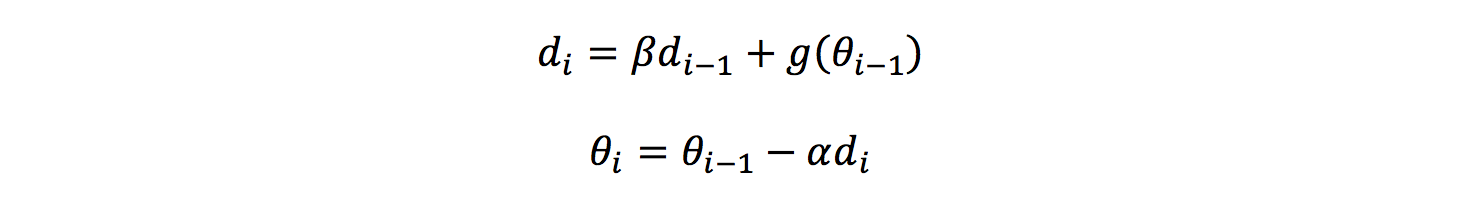
3.tf.train.AdamOptimizer()
是利用自适应学习率的优化算法,Adam算法和随机梯度下降算法不同。随机梯度下降算法保持单一的学习率更新所有的参数,学 习率在训练过程中并不会改变。而Adam算法通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率。
学习率:
决定每次参数更新的幅度。优化器中都需要一个叫做学习率的参数,使用时,如果学习率选择过大会出现震 荡不收敛的情况,如果学习率选择过小,会出现收敛速度慢的情况。我们可以选个比较小的值填入,比如0.01、0.001。
代码实现参考Github:back.py
进阶:反向传播参数更新推导过程(过程长且复杂,想要了解的小伙伴私信我)