一.概述
绝大多数的任务执行的都非常快,个别的任务执行很慢。例如有1000个reduce,995个任务都能在1分钟内执行完,但是剩余的5个任务却要执行一两个小时。
例如:You这个key,在三个节点上共有12条数据,被copy到一个reduce上执行。Are The One三个均对应一条数据,因此另外3个reduce只需要处理1条数据即可。第一个Reduce处理的时间是其他3个reduce的12倍,整个job的最终完成执行时间由最慢reduce决定。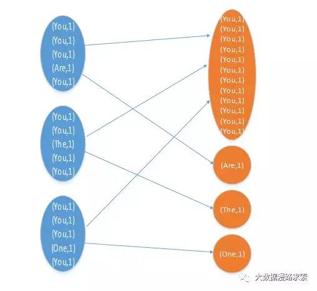
二.发生原因
- key 分布不均匀
- 业务数据本身的特性
- 建表考虑不周全
- 某些 HQL 语句本身就存在数据倾斜
三.定位数据倾斜
数据倾斜发生在shuffle过程。
| 关键词 | 情形 | 后果 |
|---|---|---|
| join | 其中一个表较小,但key集中 | 分发到某个或几个reduce的数据远高于平均值 |
| 大表与大表,0值或空值过多 | 空值由一个reduce处理,很慢 | |
| group by | 维度过小,某值数量过多 | 处理某值的reduce耗时 |
| count distinct | 某特殊值过多 | 处理此特殊值的reduce耗时 |
count(distinct)比group by更消耗内存。
Spark算子:GROUPBYKEY、REDUCEBYKEY、AGGREGATEBYKEY、JOIN、COGROUP等。
四.数据倾斜解决方案
1.过滤掉发生数据倾斜的key
场景:如果发现导致数据倾斜的key就是那么几个,而且这些数据不是很重要,那么很适合采用这种方案。比如99%的key都对应了10条数据,但是只有一个key对应1000万条数据,从而导致了数据倾斜。
2.Map端部分聚合与负载均衡
原理:Map端部分聚合,从而减轻清洗阶段数据传输和Reduce阶段的执行时间,提升总体性能。相当于Combiner。
设置:set hive.map.aggr=true
3.开启负载均衡
原理:开启后生成的执行计划会有两个MR job。第一个MR job中,相同group by key可能会被发送到不同的reduce中。第二个MR job中,相同的group by key分布到同一个reduce中。数据倾斜时,该变量设置为true,Hive会自动进行负载均衡。
设置:set hive.groupby.skewindata=true
4.将普通join改成map join
场景:
(1)关联操作中有一张表非常小
(2)不等值的join操作(a.x < b.y 或者 a.x like b.y等)
原理:
通常情况下,要连接的各个表里面的数据会分布在不同的Map中进行处理。即同一个Key对应的Value可能存在不同的Map中。这样就必须等到Reduce中去连接。
mapjoin会把小表全部读入内存中,在map阶段直接拿另外一个表的数据和内存中表数据做匹配,由于mapjoin是在map是进行了join操作,省去了reduce的运行,效率也会高很多。
mapjoin还有一个很大的好处是能够进行不等连接的join操作,如果将不等条件写在where中,那么mapreduce过程中会进行笛卡尔积,运行效率特别低。因为普通的join 需要在reduce端进行不等值判断,map端只能过滤掉where中等值连接时候的条件,如果使用mapjoin操作,在map的过程中就完成了不等值的join操作,效率会高很多。
过程:
(1)Task A(Local Task),负责扫描小表b的数据,将其转换成一个HashTable的数据结构,并写入本地的文件中,之后将该文件加载到DistributeCache中。
(2)Task B(一个没有Reduce的MR),启动MapTasks扫描大表a,在Map阶段,根据a的每一条记录去和DistributeCache中b表对应的HashTable关联,并直接输出结果。
设置:
小表自动选择Mapjoin,自动对表,若是小表就加入内存,即对小表使用Map join。
set hive.auto.convert.join=true;
小表阀值,设置小表不超过多大时开启 mapjoin 优化,默认值:25M
set hive.mapjoin.smalltable.filesize=25000000(字节);
5.提高Hive的执行并行度
场景:在Hive语句里面,同一个SQL会有多个job,默认情况下,这些job都是顺序执行的,这种情况下可以采用并行度的方案。
原理:如果每个job没有前后依赖关系,可以并发执行的话,可以通过设置该参数实现job并发执行。
设置:
开启并行。
et hive.exec.parallel=true
设置并行数,默认8。
set hive.exec.parallel.thread.number=8
6.使用随机前缀扩容
场景:如果两个大表进行关联的时候,有大量的key导致数据倾斜。
原理:在这个hive表的每条数据都加一个n以内的随机前缀。将原先一样的key通过附加随机数的方式变成不一样的key,然后就可以将这些处理后的“不同key”分散到不同的reduce中执行。
7.给空值分配随机的key值
原理:因为空值都由一个reduce处理,分配后分散处理。