机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,L1正则化和L2正则化,或者L1范数和L2范数。
1.概述
使用L1正则化的模型建叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。
Lasso回归的损失函数,式中加号后面一项α||w||1即为L1正则化项。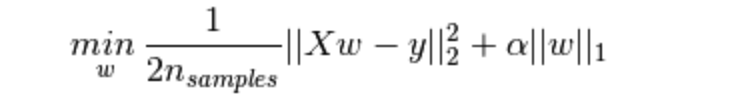
Ridge回归的损失函数,式中加号后面一项α||w||22即为L2正则化项。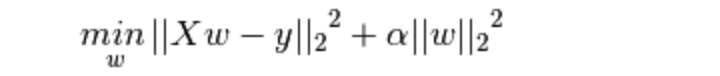
2.说明
一般回归分析中回归w表示特征的系数,从上式可以看到正则化项是对系数做了处理(限制)。
L1正则化和L2正则化的说明如下:
- L1正则化是指权值向量w中各个元素的绝对值之和,通常表示为||w||1
- L2正则化是指权值向量w中各个元素的平方和然后再求平方根(可以看到Ridge回归的L2正则化项有平方符号),通常表示为||w||2
一般都会在正则化项之前添加一个系数,Python中用α表示,一些文章也用λ表示。这个系数需要用户指定。
那添加L1和L2正则化有什么用?
下面是L1正则化和L2正则化的作用,这些表述可以在很多文章中找到。
- L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
- L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合
稀疏模型与特征选择
上面提到L1正则化有助于生成一个稀疏权值矩阵,进而可以用于特征选择。为什么要生成一个稀疏矩阵?
稀疏矩阵指的是很多元素为0,只有少数元素是非零值的矩阵,即得到的线性回归模型的大部分系数都是0. 通常机器学习中特征数量很多。在预测或分类时,那么多特征显然难以选择,但是如果代入这些特征得到的模型是一个稀疏模型,表示只有少数特征对这个模型有贡献,绝大部分特征是没有贡献的,或者贡献微小(因为它们前面的系数是0或者是很小的值,即使去掉对模型也没有什么影响),此时我们就可以只关注系数是非零值的特征。这就是稀疏模型与特征选择的关系。
3.理解
那么,如何解释L1正则化可以产生稀疏模型,L2正则化产生平滑的权值,防止过拟合呢?
公式来看
L1带正则化项的损失函数,J是MSE,α 是正则化系数: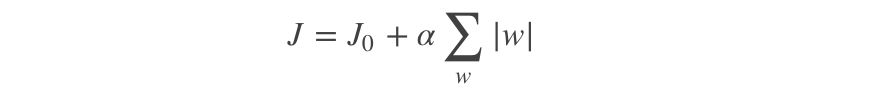
L2带正则化项的损失函数: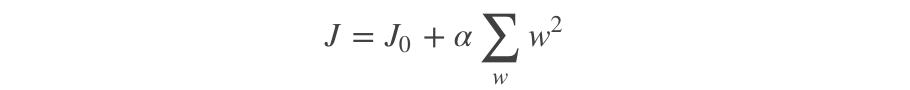
去掉损失函数后,L1和L2的梯度(导数的反方向)为: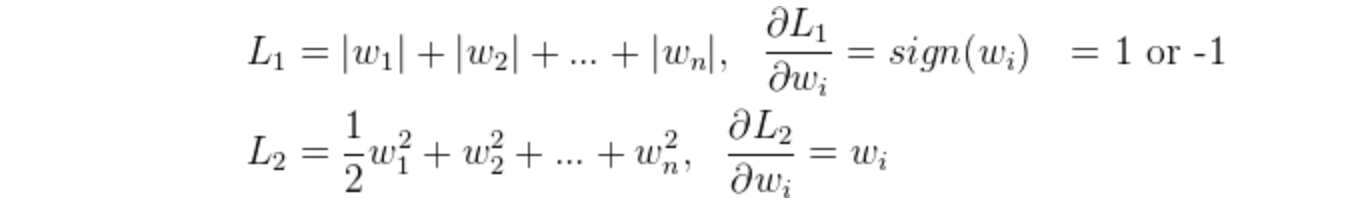
所以(不失一般性,我们假定:w等于不为0的某个正的浮点数,学习速率η 为0.5):
L1的权值更新公式为w = w - η*1 = w - 0.5*1,也就是说权值每次更新都固定减少一个特定的值(比如0.5),那么经过若干次迭代之后,权值就有可能减少到0。
L2的权值更新公式为w = w - η*w = w - 0.5*w,也就是说权值每次都等于上一次的1/2,那么,虽然权值不断变小,但是因为每次都等于上一次的一半,所以很快会收敛到较小的值但不为0。
L1能产生等于0的权值,即能够剔除某些特征在模型中的作用(特征选择),即产生稀疏的效果。
L2可以得迅速得到比较小的权值,但是难以收敛到0,所以产生的不是稀疏而是平滑的效果。
图像来看
二维空间,图中等值线是J0的等值线,黑色方形和圆形是L函数的图形。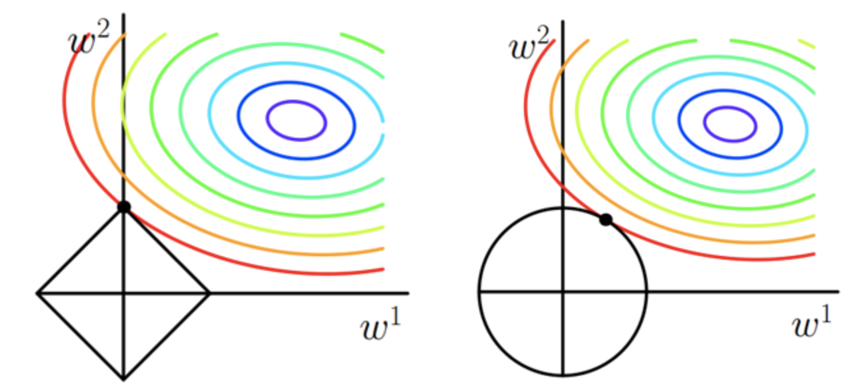
左图是L1正则化,右图是L2正则化。
L1正则化的函数有很多『突出的角』(二维情况下四个,多维情况下更多),J0与这些角接触的机率会远大于与L其它部位接触的机率,而在这些角上,会有很多权值等于0,这就是为什么L1正则化可以产生稀疏模型,进而可以用于特征选择。
下L2正则化的函数图形是个圆,与方形相比,被磨去了棱角。因此J0与L相交时使得w1或w2等于零的机率小了许多,这就是为什么L2正则化不具有稀疏性的原因。
L1中两个权值倾向于一个较大另一个为0,L2中两个权值倾向于均为非零的较小数。这也就是L1稀疏,L2平滑的效果。
4.总结
L1正则化,也叫LASSO回归:
有助于使特征带入模型后形成稀疏矩阵,过滤掉一些没有贡献的特征,可用于特征选择。
L2正则化,也叫岭回归:
使参数更新更加平滑,过度更加缓和,使模型更加稳定,使模型的“抗扰动能力”更好,也就是可以防止过拟合。
L1和L2都有防止模型过拟合的作用。