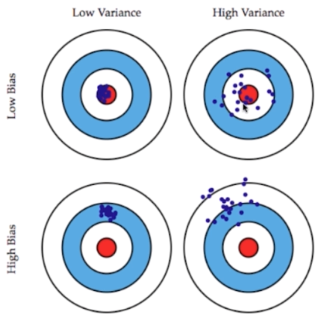
学习算法的预测误差, 或者说泛化误差可以分解为三个部分: 偏差(bias), 方差(variance) 和噪声(noise)。在估计学习算法性能的过程中, 我们主要关注偏差与方差. 因为噪声属于不可约减的误差。
1.偏差和方差
模型误差 = 偏差(bias) + 方差(Variance) + 不可避免的误差
方差
方差度量了同样大小的训练集的变动所导致的学习性能的变化, 即刻画了数据扰动所造成的影响。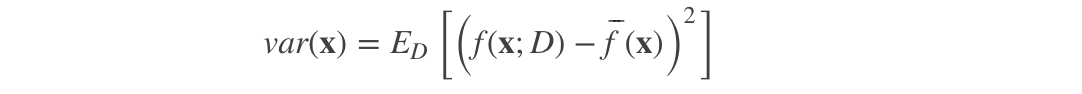
数据的一点点扰动都会较大地影响模型。
通常通常原因,使用的模型太复杂。
如高阶多项式回归。
方差大,过拟合overfitting。
偏差
偏差度量了学习算法的期望预测与真实结果的偏离程度, 即刻画了学习算法本身的拟合能力。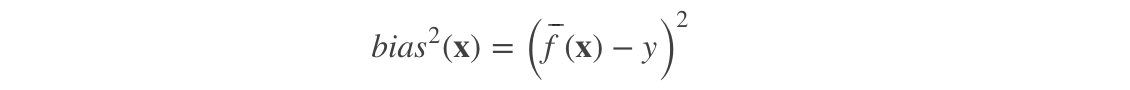
导致偏差的主要原因:
对问题本身的假设不正确。
如:非线性数据使用线性回归
偏差大,欠拟合underfitting。
噪声
噪声表达了在当前任务任何学习算法所能达到的期望泛化误差的下界, 即刻画了学习问题本身的难度。
巧妇难为无米之炊, 给一堆很差的食材, 要想做出一顿美味, 肯定是很有难度的.
2.讨论
非参数学习通常是高方差算法,如KNN。
因为不对数据进行任何假设。
参数学习通常是高偏差算法,如线性回归。
因为线性回归具有极强的假设。
大多数算法具有相应的参数,可以调整偏差和方差。
如KNN中的K。
如线性回归中多项式回归中的阶数。
偏差和方差通常是矛盾的。
降低偏差,会提高方差。
降低方差,会提高偏差。
机器学习的主要挑战,来自于方差!
解决高方差的通常手段:
1.降低模型复杂度
2.减少数据维度;降噪
3.增加样本数
4.使用验证集
5.模型正则化