Apache Flink 是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个 Flink 运行时(Flink Runtime),提供支持流处理和批处理两种类型应用的功能。
概述
现有开源计算方案中,会把流处理和批处理作为两种不同的应用类型:流处理一般需要支持低延迟、Exactly-once保证,而批处理需要支持高吞吐、高效处理。实现批处理的开源方案有 MapReduce、Tez、Crunch、Spark,实现流处理的开源方案有 Samza、Storm。 Flink 将二者统一起来:Flink 是完全支持流处理,也就是说作为流处理看待时输入数据流是无界的;批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。基于同一个Flink运行时(Flink Runtime),分别提供了流处理和批处理API,而这两种API也是实现上层面向流处理、批处理类型应用框架的基础。
Flink 是一款新的大数据处理引擎,目标是统一不同来源的数据处理。这个目标看起来和 Spark 和类似。这两套系统都在尝试建立一个统一的平台可以运行批量,流式,交互式,图处理,机器学习等应用。所以,Flink 和 Spark 的目标差异并不大,他们最主要的区别在于实现的细节。
Flink 技术栈如下。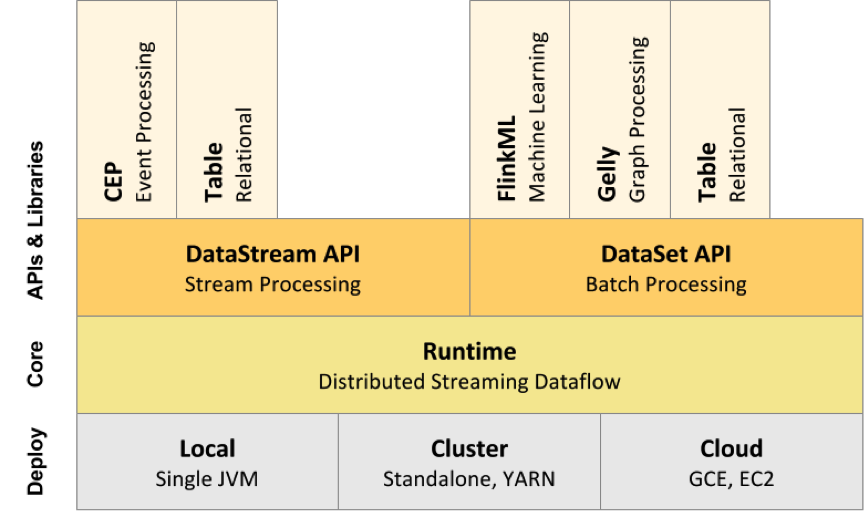
比较
了解 Flink 的作用和优缺点,与 Spark 来对比阐述。从抽象层,内存管理,语言实现,以及 API 和 SQL 等方面来描述。
抽象层
Spark 批处理任务,可以使用 RDD,而对于流处理,可以使用 Streaming(RDD,实质批处理)。
Flink 批处理用 DataSet,对于流处理,有 DataStreams。
DataSet 和 DataStream 是相对独立的 API,在 Spark 中,所有不同的 API,比如 Streaming,DataFrame 都是基于 RDD 抽象的。然而在 Flink 中,DataSet 和 DataStream 是同一个公用引擎之上的两个独立的抽象。
内存管理
Spark 延用 Java 的内存管理来做数据缓存,这样很容易导致 OOM 或者 GC。之后,Spark 开始转向另外更加友好和精准的控制内存,即:Tungsten 项目。
Flink 从一开始就坚持使用自己控制内存。Flink 除把数据存在自己管理的内存之外,还直接操作二进制数据。在 Spark 1.5之后的版本开始,所有的 DataFrame 操作都是直接作用于 Tungsten 的二进制数据上。
语言实现
Spark 使用 Scala 来实现的,它提供了 Java,Python 以及 R 语言的编程接口。而对于 Flink 来说,它是使用 Java 实现的,提供 Scala 编程 API。从编程语言的角度来看,Spark 略显丰富一些。
API
对于 Streaming,Spark 把它看成更快的批处理,而 Flink 把批处理看成 Streaming 的特殊例子,差异如下:其一,在实时计算问题上,Flink 提供了基于每个事件的流式处理机制,所以它可以被认为是一个真正意义上的流式计算,类似于 Storm 的计算模型。对于 Spark 来说,不是基于事件粒度的,而是用小批量来模拟流式,也就是多个事件的集合。所以,Spark 被认为是一个接近实时的处理系统。虽然,大部分应用实时是可以接受的,但对于很多应用需要基于事件级别的流式计算。因而,会选择 Storm 而不是 Spark Streaming,现在,Flink 也许是一个不错的选择。
SQL
Spark SQL 是其组件中较为活跃的一部分,它提供了类似于 Hive SQL 来查询结构化数据,API 依然很成熟。对于 Flink 来说,截至到目前 1.0 版本,只支持 Flink Table API,官方在 Flink 1.1 版本中会添加 SQL 的接口支持。
特性
- 高吞吐 & 低延时
- 支持 Event Time & 乱序事件
- 状态计算的 Exactly-Once 语义
- 高度灵活的流式窗口
- 带反压的连续流模型
- 容错性
- 流处理和批处理共用一个引擎
- 内存管理
- 迭代 & 增量迭代
- 程序调优
- 流处理应用
- 批处理应用
- 类库生态
- 广泛集成
对比
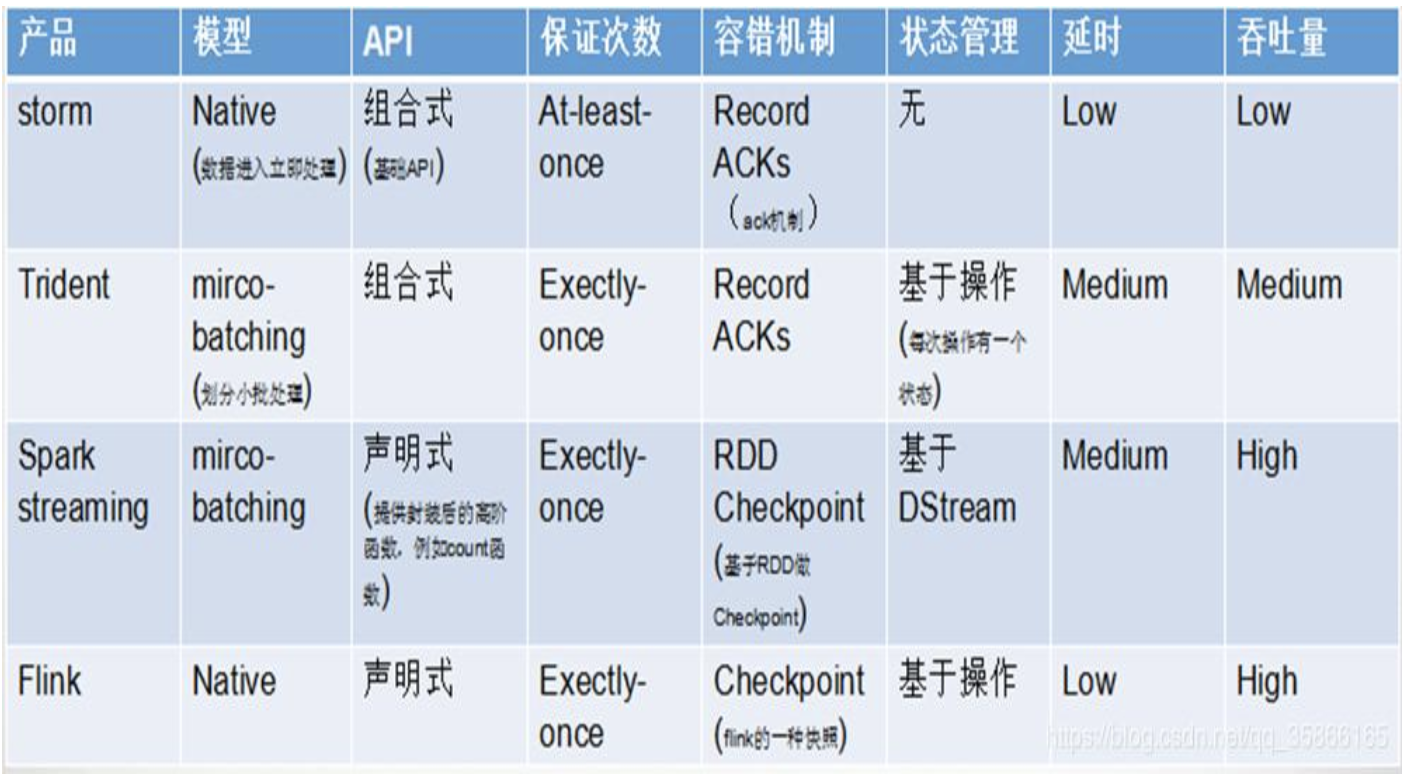
- 相比于storm ,spark和flink两个都支持窗口和算子,减少了不少的编程时间
- flink相比于storm和spark,flink支持乱序和延迟时间(在实际场景中,这个功能很牛逼),个人觉得就这个功能就可以锤爆spark
- 对于spark而言他的优势就是机器学习,如果我们的场景中对实时要求不高可以考虑spark,但是如果是要求很高就考虑使用flink,比如对用户异常消费进行监控,如果这个场景使用spark的话那么等到系统发现开始预警的时候(0.5s),罪犯已经完成了交易,可想而知在某些场景下flink的实时有多重要。
分布式系统评价
At Most once,At Least once和Exactly once
在分布式系统中,组成系统的各个计算机是独立的。这些计算机有可能fail。
一个sender发送一条message到receiver。根据receiver出现fail时sender如何处理fail,可以将message delivery分为三种语义:
At Most once: 对于一条message,receiver最多收到一次(0次或1次).
可以达成At Most Once的策略:
sender把message发送给receiver.无论receiver是否收到message,sender都不再重发message.
At Least once: 对于一条message,receiver最少收到一次(1次及以上).
可以达成At Least Once的策略:
sender把message发送给receiver.当receiver在规定时间内没有回复ACK或回复了error信息,那么sender重发这条message给receiver,直到sender收到receiver的ACK.