Hive是由Facebook实现并开源,基于hadoop的一个数据仓库工具。
Hive可以将结构化的数据映射为一张数据库表,提供Hive SQL查询,底层数据存储在HDFS之上。Hive的实质是将SQL语句转换为MR任务运行。
基于HDFS的计算框架,对HDFS上的数据分析和管理。
1.为什么使用Hive
直接使用MR的问题:
1.学习成本高
2.MR实现复杂查询开发难度大
Hive优点:
1.可扩展:自由宽展几圈规模,一般不需要重启。
2.延展性:Hive支持自定义函数。
3.良好容错性:保证有节点出现问题,SQL语句仍可完成执行。
2.Hive架构
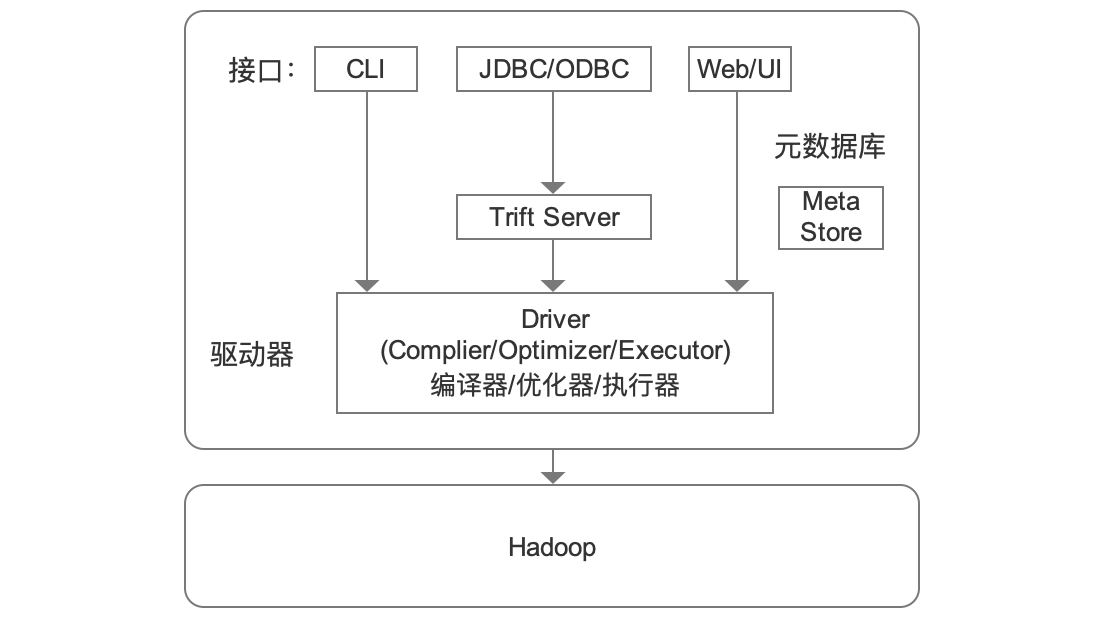
用户接口:
CLI:shell命令行,最常用。
JDBC/ODBC:开发过程连接 Hive Server。
WEB UI:浏览器访问。
跨语言服务:
Thrift Server,常用hiveserver2,能让不同的编程语言调用Hiver接口。
驱动程序
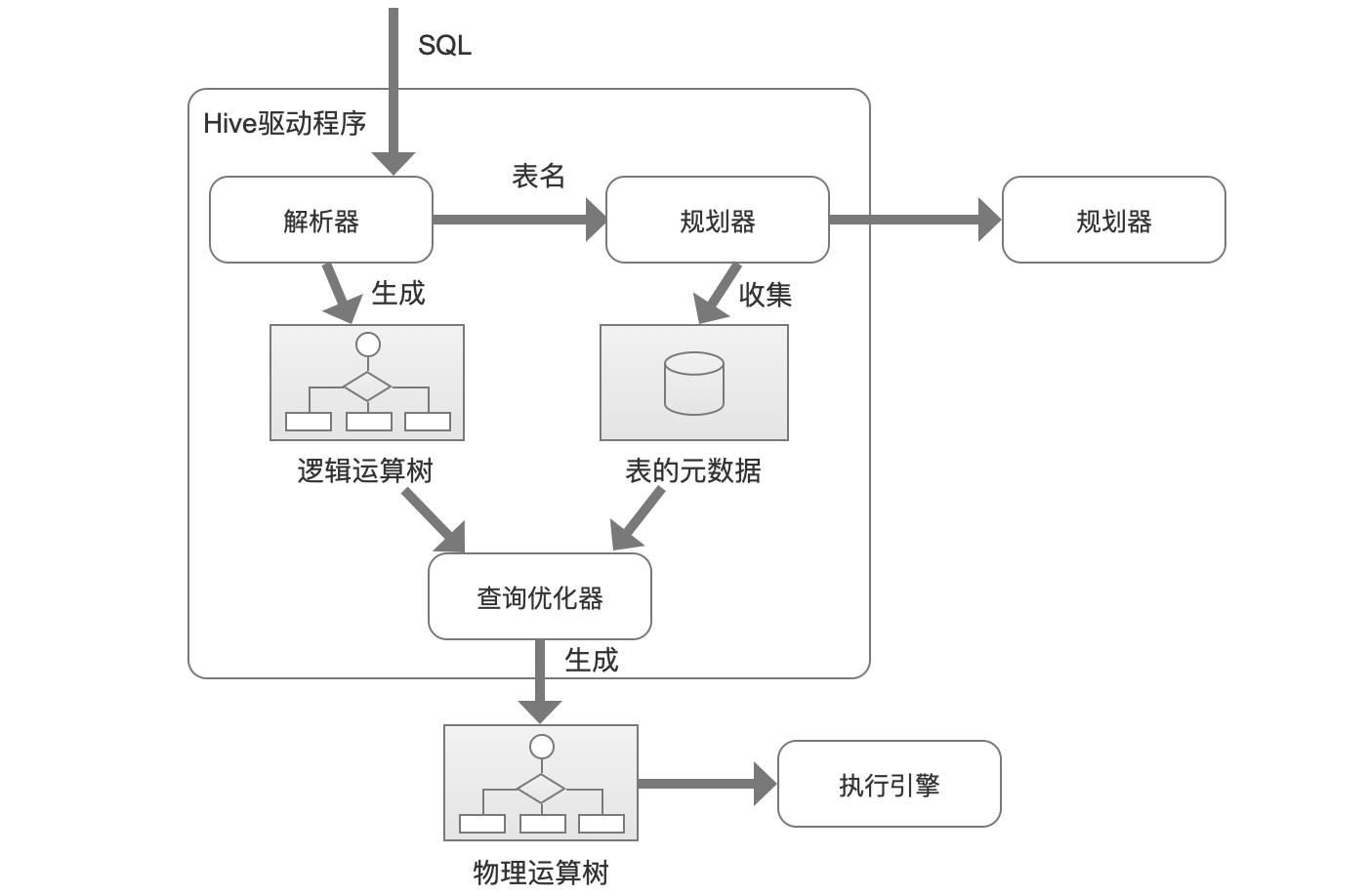
(1)解释器解析SQL语句并生成一个抽象语法树(AST),他描述了为生成结果所必须执行的逻辑运算,例如SELECT、JOIN、UNION、分组、投影等。
(2)规划器在Hive Metastore中检索表的元数据,包括HDFS文件的位置、存储格式、行数等。
(3)查询优化器使用AST和表的元数据,生成一个物理运算树,即所谓的执行计划,它描述了为检索数据所必须执行的所有物理运算,例如嵌套循环链接、排序合并连接等。
查询优化器生成的执行计划最终决定了将在Hadoop集群上执行的任务。
(4)元数据
即对数据的描述,表的行,列,属性。
是存储在Mysql或Derby数据库中(RDMS)。
3.Hive和RDMS对比
| Hive | RDMS | |
|---|---|---|
| 查询语言 | SQL | RDMS |
| 数据存储 | HDFS | Raw Device or Local FS |
| 执行器 | MapReduce | Executor |
| 数据插入 | 支持批量导入单条导入 | 支持单条批量导入 |
| 数据操作 | 覆盖追加 | 行级更新删除 |
| 处理数据规模 | 大 | 小 |
| 执行延迟 | 高 | 低 |
| 分区 | 支持 | 支持 |
| 索引 | 0.8之后加入简单索引 | 支持复杂索引 |
| 扩展性 | 高(好) | 有限(差) |
| 数据加载模式 | 读时模式(快) | 写时模式(慢) |
| 应用场景 | 海量数据查询 | 实时查询 |