分区是一种根据分区列的(partition column,如日期等)的值对表进行粗略划分的机制。采用的也是hadoop分而治之的思想。
简介
我们知道,hive的表存储在hdfs之上,建立一个数据库,会在/user/hive/warehouse/目录下生成一个.db文件夹,如果继续在此数据库中添加表,则会在.db文件下创建子文件夹。
如果不使用分区表,一张表下只有一个文件,创建分区后表一张表下会有多个文件。分区就是在hdfs上建立文件夹,把分区数据放在不同文件夹下,这样查询的时候就不用扫描整张表,扫描分区就行了,加快了查询速度。
实例演示:
下图是没进行分区的表info,因为我直接load本地文件,所以是一个txt文件。
注意:hive是数据仓库,不支持insert,需要从本地或者hdfs进行load,或者选择其他的表overwrite。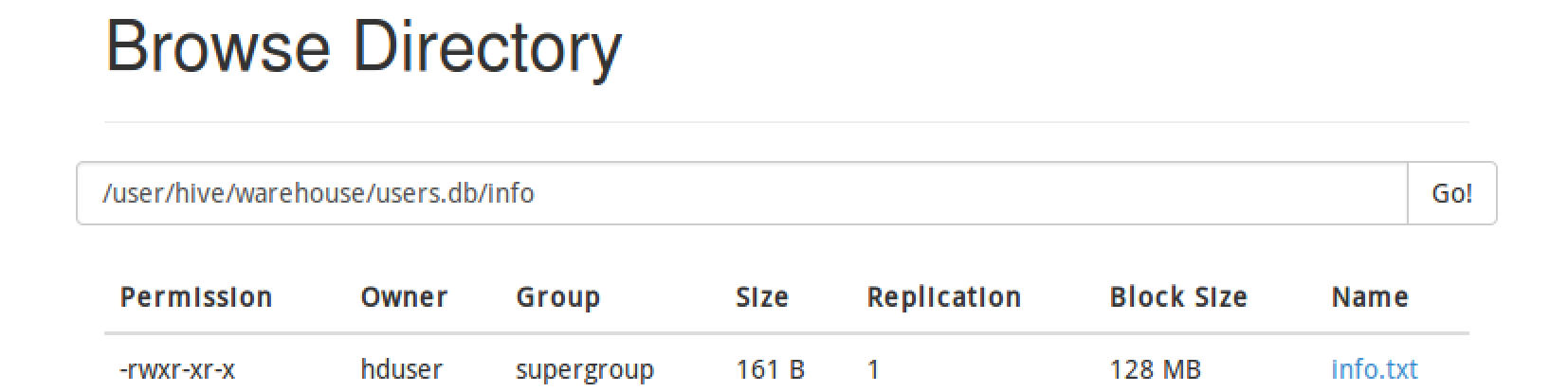
接下来创建一个分区表info_part,使用overwrite语句在info表中选择数据进行加载。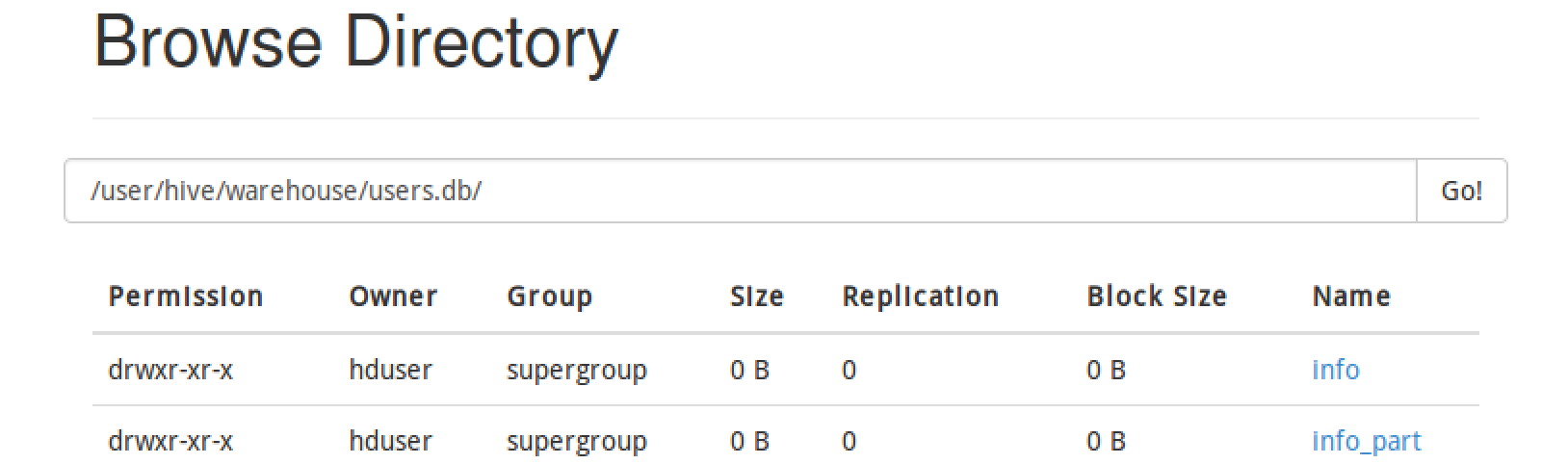
两类分区
hive中支持两类分区,静态分区和动态分区,平时用的比较多的是动态分区,因为静态分区比较费时费力。
静态分区是自己指定分区的参数,而动态则可以根据某个字段自动分区。
静态分区:1
insert overwrite table info_part PARTITION (addr='qiqihaer') select name,age,sex from info;
动态分区:1
insert overwrite table info_part PARTITION (addr) select name,age,sex,addr from info;
我们可以看到在info_part文件夹下,每个分区都是一个文件夹。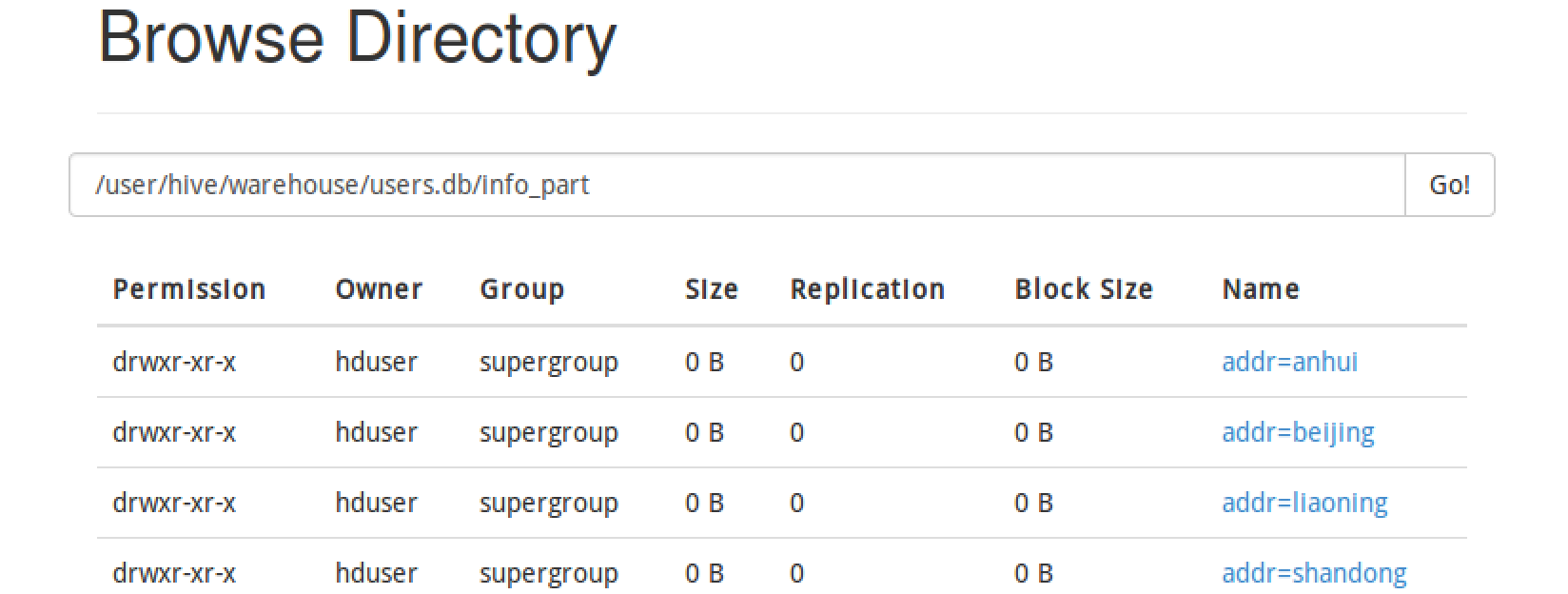
注意:使用动态分区要设置两个选项:
set hive.exec.dynamic.partition=true;
默认值:false
描述:是否允许动态分区
set hive.exec.dynamic.partition.mode=nonstrict;
默认值:strict
描述:strict是避免全分区字段是动态的,必须有至少一个分区字段是指定有值的