特点:
- 速度快。数据保存到内存,使用DAG调度程序。
- 易用。支持scala,java,python等语言编写程序。
- 通用。结合Spark SQL,Spark Streaming,Spark Core,MLlib,Graphx无缝集成。
- 到处运行。Spark可以运行在hadoop,yarn,能够读取HDFS,Hbase。
Spark Core:
spark生态圈核心,是一个分布式大数据处理框架。
1.多种并行模式
2.提供DAG
3.引入RDD
Spark Streaming:
对实时数据进行高吞吐,高容错的流处理系统。
1.动态负载均衡,划分小数据。
2.快速故障恢复,某节点故障。
3.批处理,流处理,交互分析一体。
处理流程
1.将数据按时间间隔分批,也就是离散化。(DStream)
2.每一段都通过Spark(此时理解成一个队列)转换成RDD。
3.对RDD进行处理。
Spark SQL:
主要用于结构化数据处理。
前身是Shark,Shark即Hive on Spark。Shark依赖Hive,MR,存在瓶颈。
数据集有:RDD,DataFram
Spark MLlib:机器学习组件。
Spark GraphX:分布式图计算框架。
Spark运行架构
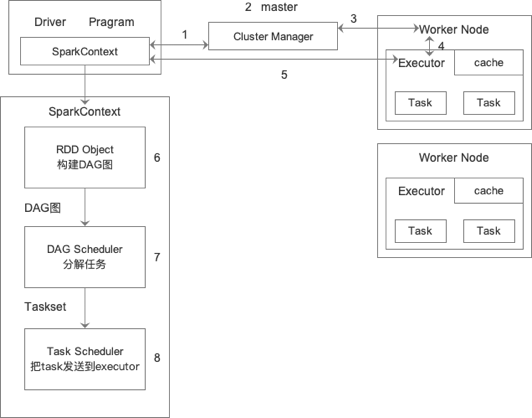
1.Driver和master连接并申请资源。
2.master进行资源调度。
3.master跟Worker进行RPC通信,让Worker启动Executor。
4.启动Executor。
5.Executor进行通信。
6.RDD依赖生成DAG图。
7.RDD触发Action,从后往前,宽依赖就shuffe切分stage。由ADG Scheduler完成。每个stage里有一个或多个任务,每个stage是一个调度阶段。
8.Task Scheduler接收来自DAG Scheduler的任务集,以任务的形式一个个分发到Woker的Executor中运行。(序列化)
9.Executor接收到Task,将Task反序列化,执行任务。
Spark支持的文件格式

Spark1和Spark2版本区别
Spark1和Spark2区别
1 Spark2 Apache Spark作为编译器:增加新的引擎Tungsten执行引擎,比Spark1快10倍。
2 ml做了很大的改进,支持协同过滤。
3 Spark2加了SparkSession把Spark的SQLcontext和hiveContext整合,dataFrame与dataset整合,统一采用dataset。
4 做流的方式,例如设置10秒钟一批,5秒钟处理。
5 R语言API加入了很多机器学习的算法。