过拟合(over-fitting )和欠拟合(under-fitting)是我们在机器学习建模中常会遇到的两种情况,文章会介绍两种情况出现的原因和解决方法。
欠拟合 under-fitting
算法所训练的模型不能完整表达数据关系。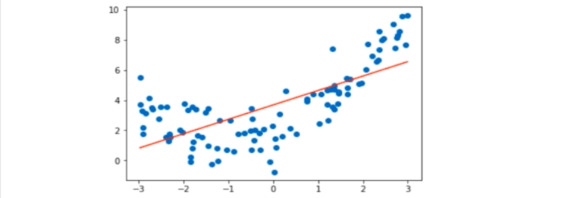
原因:
- 特征量少
- 模型复杂度过低
解决:
- 增加新特征
- 增加模型复杂度
过拟合 over-fitting
算法所训练的模型过多地表达了数据间的噪声关系。
训练集表现好,测试集不能正确分类,泛化能力差。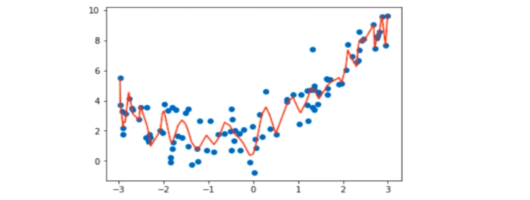
原因:
- 训练集和测试集特征不一致
- 数据噪声太大
- 特征量太多
- 模型太复杂
- 训练集占总数据比例小
解决:
- 重新清洗数据
- 增大数据训练量
- 使用正则化方法
学习曲线
1.模型复杂度曲线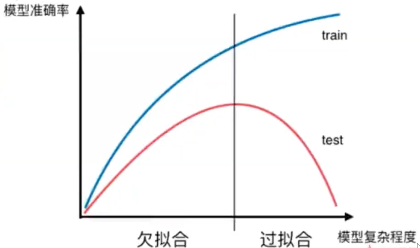
我们想要找到泛化能力最好的地方。理论的模型,针对不同数据,不同模型,可能绘制不出这样清晰的曲线。例如KNN和多项式回归,不适合绘制,虽然它们内在符合这样的逻辑。后续的决策树适合绘制这样的曲线。
2.学习曲线
通过学习曲线,也可以清晰地看到模型的过拟合,欠拟合。
学习曲线:随着训练样本的逐渐增多,算法训练出的模型的表现能力。
横轴:样本训练数
纵轴:损失函数MSE
欠拟合与最佳学习曲线: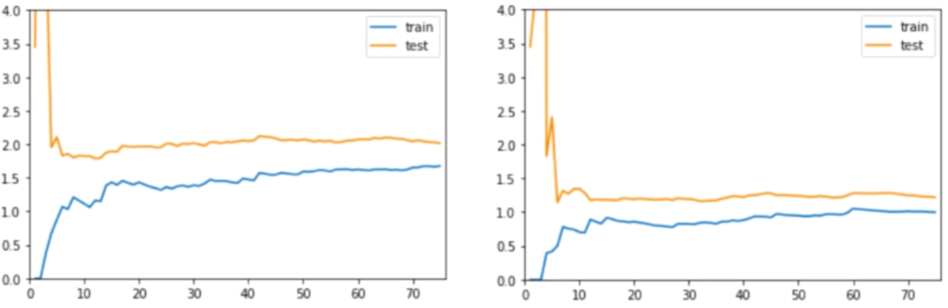
欠拟合和最佳比较,train和test趋于稳定的位置更高,说明train和test误差都较大,模型有错误。
过拟合与最佳学习曲线: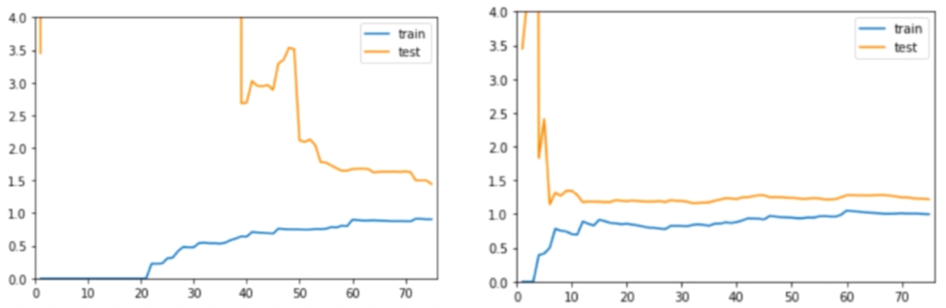
训练数据集误差不大,测试数据集误差较大,测试和训练集离的远,差距较大,说明模型的泛化能力不好,对于新的数据来说,误差比较大。