KNN算法全称K-Nearest Neighbors,是一个适合入门机器学习的算法,KNN思想简单,数学知识少,拥有机器学习完整的流程,易于理解。
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。其中K通常是不大于20的整数。
原理
绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。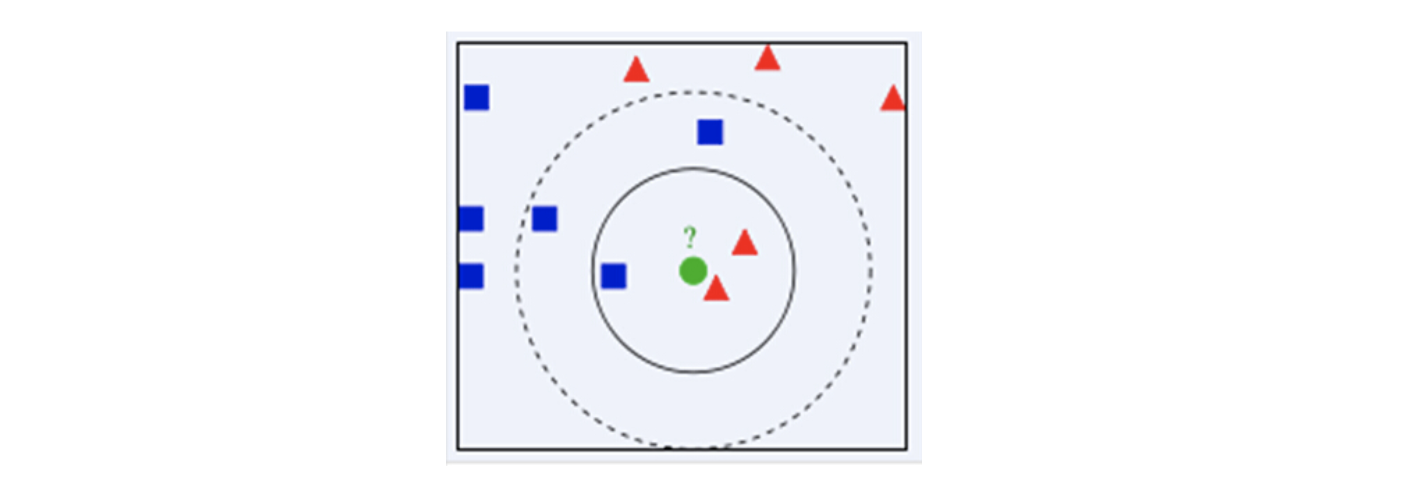
由此也说明了KNN算法的结果很大程度取决于K的选择。
优缺点
优点:
1、思想简单,理论成熟,既可以用来做分类也可以用来做回归;
2、可用于非线性分类;
3、训练时间复杂度为O(n);
4、准确度高,对数据没有假设,对outlier(离群值)不敏感;
缺点:
1、计算量大;
2、样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少);
3、需要大量的内存;
过程
1.计算测试数据与各个训练数据之间的距离(欧式距离);
2.按照距离的递增关系进行排序;
3.选取距离最小的K个点;
4.确定前K个点所在类别的出现频率;
5.返回前K个点中出现频率最高的类别作为测试数据的预测分类。
距离类型
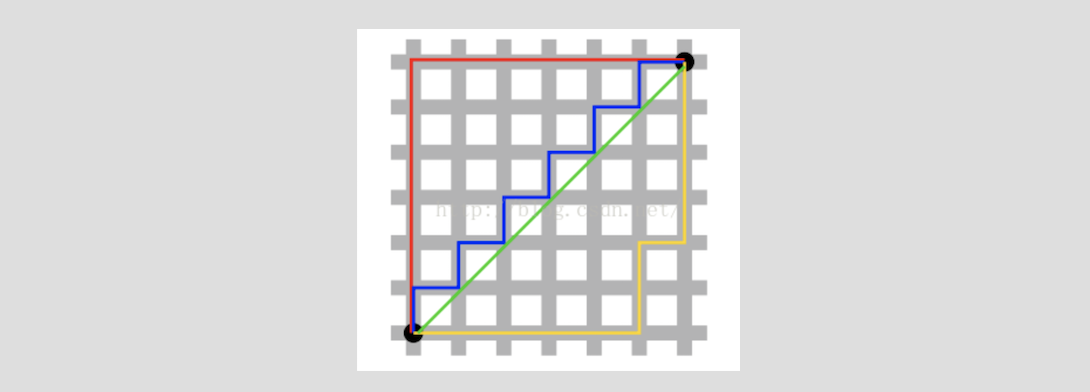
曼哈顿距离:
也可叫出租车距离,红蓝黄皆为曼哈顿距离。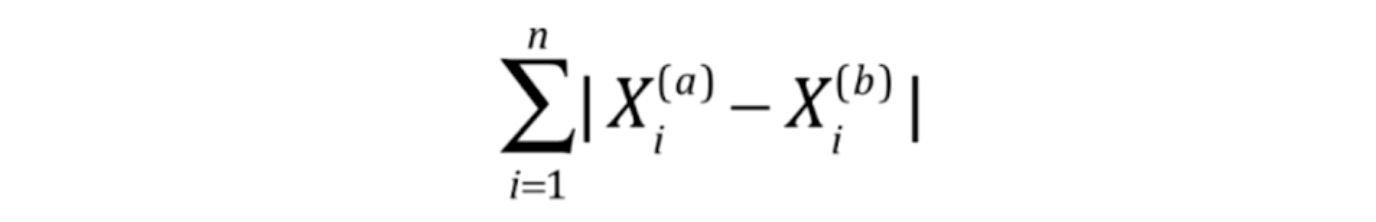
欧式距离:
两点之间距离最短,绿色为欧式距离。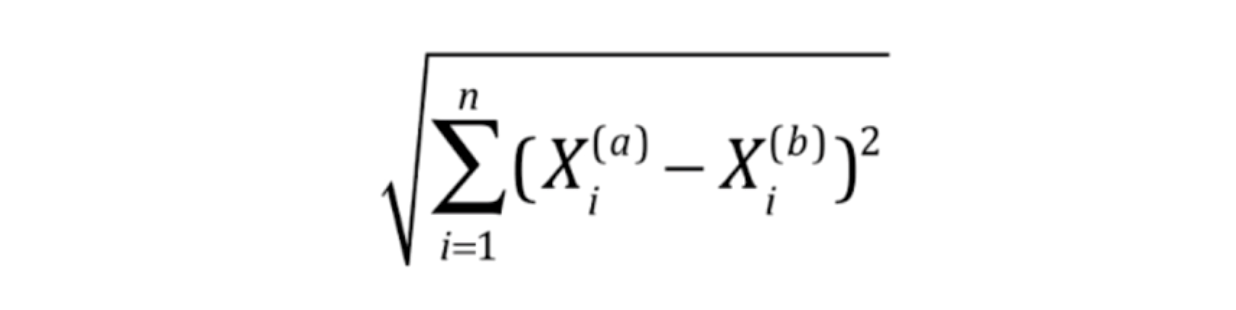
实现
KNN算法可自己编写进行实现,同时scikit-learn也对KNN算法进行了封装(只需要自己加载数据集),这里给出手动编写的KNN。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37import numpy as np
#自定义数据集
raw_data_X = [ [3,2],
[3,1],
[1,3],
[3,4],
[2,2],
[7,4],
[5,3],
[9,2],
[7,3],
[7,0] ]
#给数据集分类
raw_data_y = [0,0,0,0,0,1,1,1,1,1]
X_train = np.array(raw_data_X)
y_train = np.array(raw_data_y)
#设置待分类的点
x = np.array([8,3])
from math import sqrt
#计算待分类的点与各点的距离
distances = []
for x_train in X_train:
d = sqrt(np.sum((x_train - x)**2))
distances.append(d)
np.argsort(distances)
#由近到远排列
nearest = np.argsort(distances)
#取前6个点
k = 6
topK_y = [y_train[i] for i in nearest[:k]]
#看前6个点每个类别有多少个点
from collections import Counter
Counter(topK_y)
votes = Counter(topK_y)
#取出现最多的类别
votes.most_common(1)[0][0]
#结果为1
超参数
超参数:在算法运行前需要决定的参数。
模型参数:算法过程中学习的参数。
KNN算法中没有模型参数。
KNN中常见超参数:
K-近邻点的个数:
KNN算法中,K值需要提前指定,如何取得最优K值呢,可以使用for循环对分类器结果进行比较取得最优K。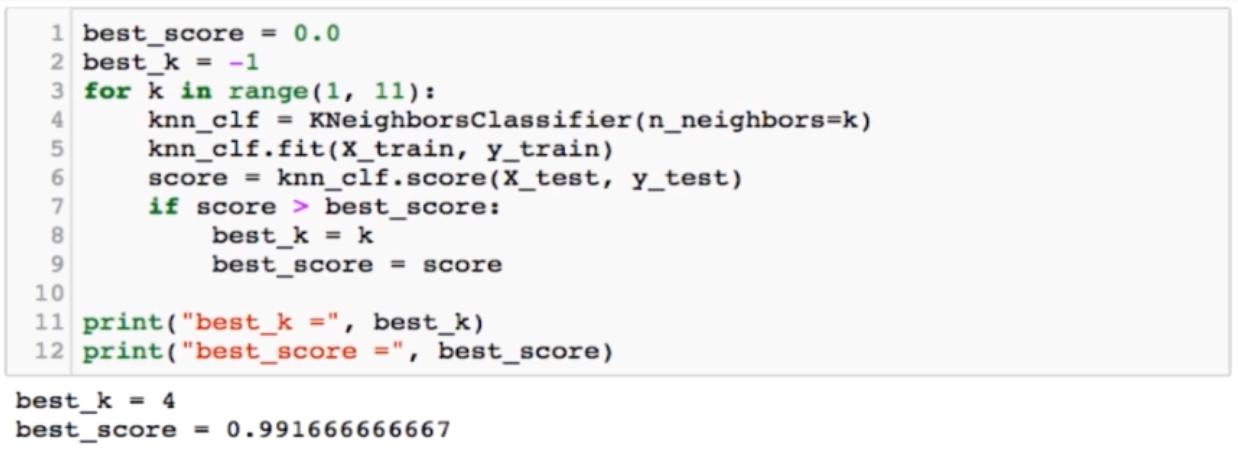
weight-距离的权重:
weight的取值有两个(考虑权重或不考虑权重):
uniform(默认,即不考虑距离):一致的权重;
distance:距离的倒数作为权重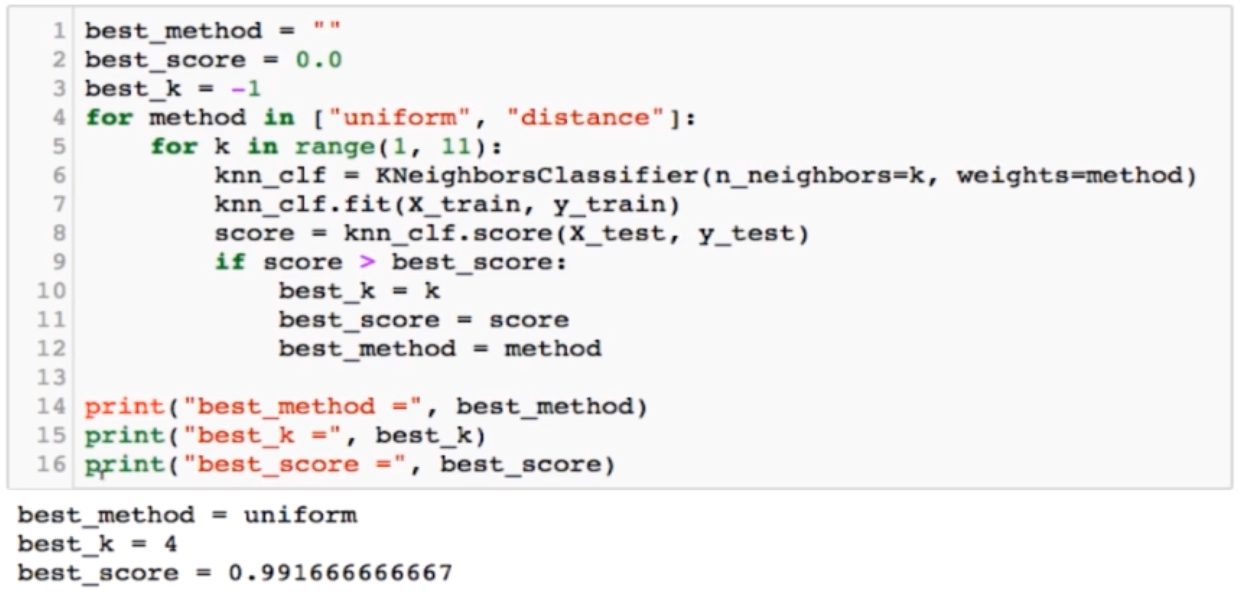
p-明可夫斯基距离中的P值:
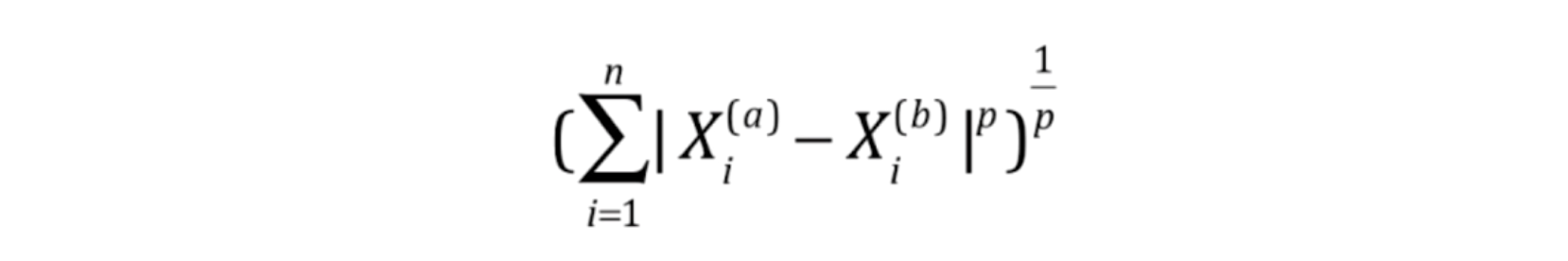
超参数存在相互依赖关系,因为考虑p的前提是weight=distance,如果weight=uniform,则不会考虑p的值。
p=1:即欧式距离;p=2:即曼哈顿距离。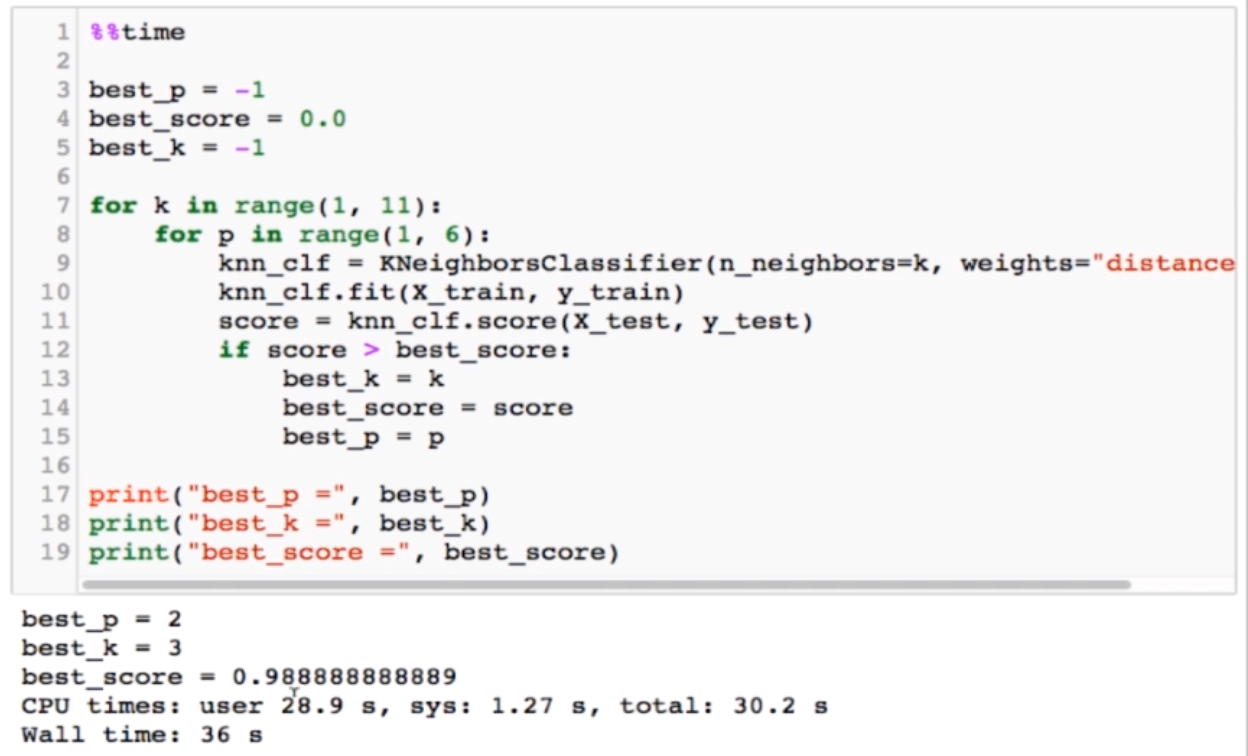
网格搜索
更好的确定最优的超参数。
数据归一化
将所有的数据映射到同一个尺度中。